
黄仁勋拿下整个日本,国运之战打响,豪赌物理AI工厂,部署1000万台机器人
黄仁勋拿下整个日本,国运之战打响,豪赌物理AI工厂,部署1000万台机器人2026年7月16日,东京。 英伟达CEO黄仁勋拍了一个大大的马屁:"日本发明了现代制造业。现在,它正在建设将驱动下一次工业革命的AI工厂。"不过效果很明显,日本被彻底忽悠瘸了,在同一天,市场估算投资额接近3.4万亿日元的项目落地(约1408亿元人民币)。
来自主题: AI资讯
8226 点击 2026-07-31 10:40
 搜索
搜索
2026年7月16日,东京。 英伟达CEO黄仁勋拍了一个大大的马屁:"日本发明了现代制造业。现在,它正在建设将驱动下一次工业革命的AI工厂。"不过效果很明显,日本被彻底忽悠瘸了,在同一天,市场估算投资额接近3.4万亿日元的项目落地(约1408亿元人民币)。

英伟达买的是企业数据的理解力。
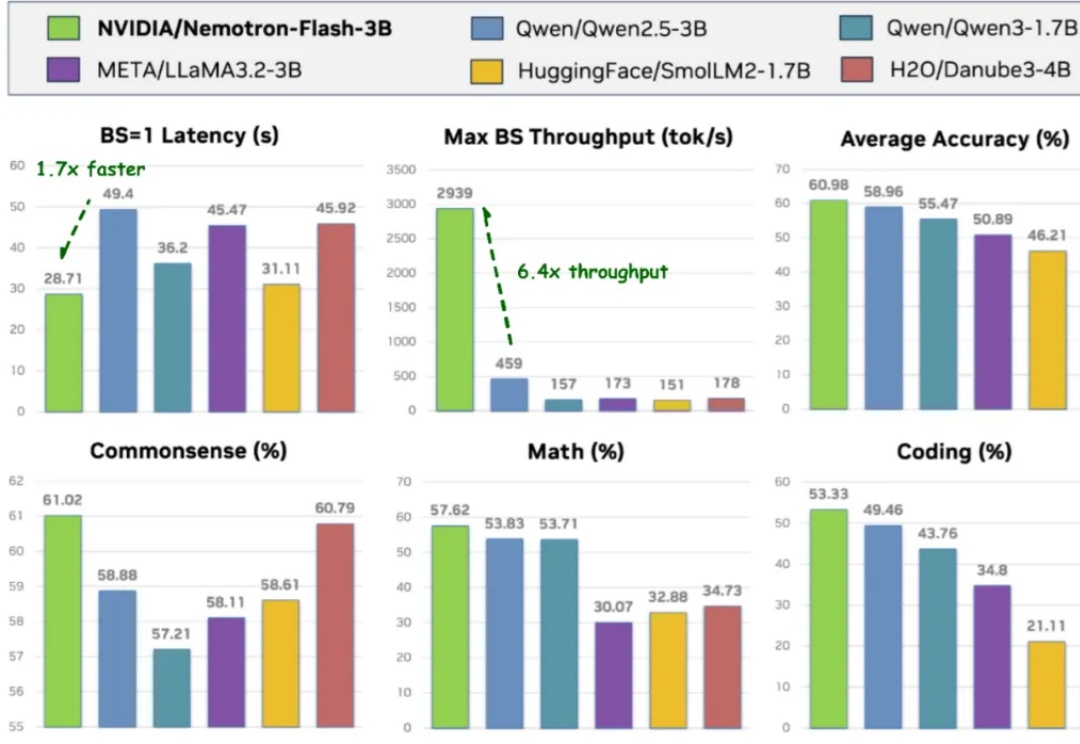
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。

一夜之间,芯片圈子简直大地震—— 英伟达正式宣布,50亿美元入股(每股23.28美元)“老对手”英特尔!英伟达正式宣布,50亿美元入股(每股23.28美元)“老对手”英特尔!

黄仁勋正在像押注OpenAI一样在中国押注未来的具身智能巨头。 英伟达给刚创办的OpenAI送超算这个事已经被大家津津乐道,现在他们正在把这个经验复用到机器人领域。
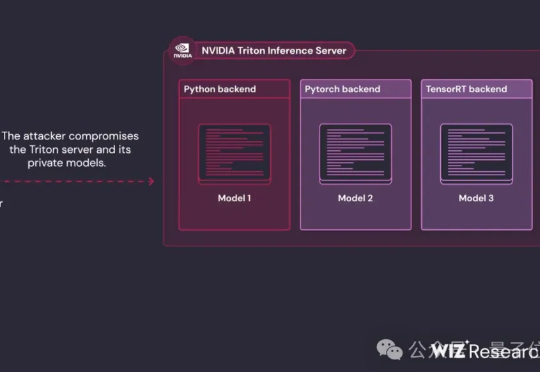
一波未平,一波又起。 英伟达Triton推理服务器,被安全研究机构Wiz Research曝光了一组高危漏洞链。
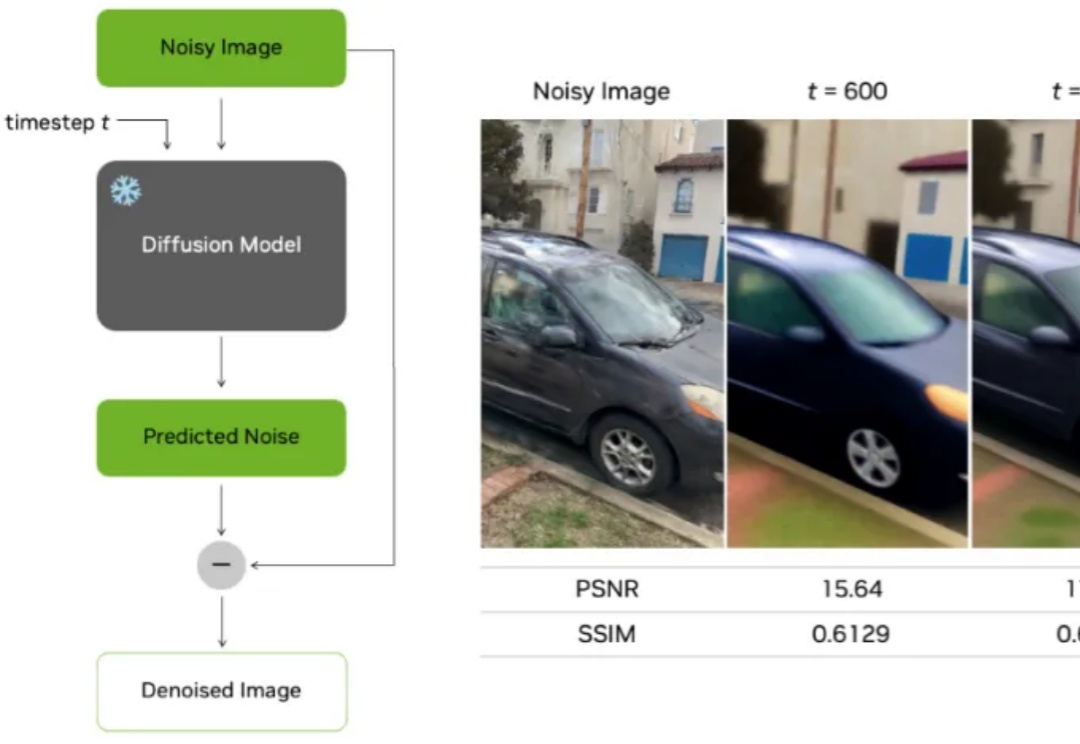
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。
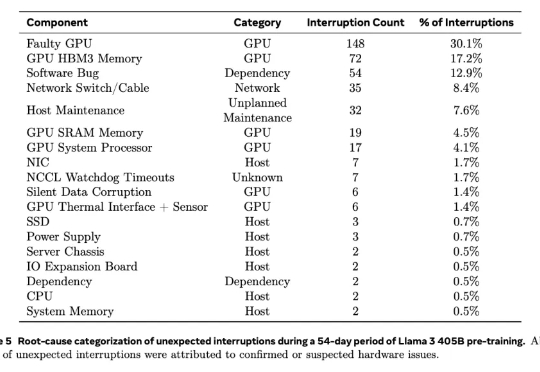
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。